



When building new projects I focus on solving problems I relate to. Since these are personal projects, I prioritize building features based on user feedback or based on my usage. Although I understand the value of writing unit tests, this becomes an after thought, since the priority is pushing the next new feature.
To get me started on building more unit tests for my projects, I built an autonomous agent to generate unit tests from SvelteKit projects. I started off by focusing purely on one SvelteKit project I built in order to validate the usefulness of my Dagger AI Agent module before generalizing it for other SvelteKit projects I have.
I specifically tested this with my more recent project; A chatbot leveraging RAG to answer questions regarding legal issues involved in investing in property in Latin America
Why Dagger?
I used Dagger for a few reasons. Some time ago, I created a module to run my unit tests locally in a consistent environment.
Dagger runs pipelines in containers, as a result, I can get the structure of the directory mounted in the container. I can use this information in the autonomous agent to ensure components are correctly imported. Additionally, since I am running my code in a container, I worry less about code running locally but not in production since the environment is consistent. This is also the rationale behind another Dagger module I built to run my unit tests locally in a consistent environment.
Scope
The objective of this build was to build an autonomous agent to generate unit tests for a given page for a SvelteKit project using Typescript.
LangChain
As a starting point, I leveraged LangChain to build the pipeline. This agent uses OpenAI as it's language model to carry out a sequence of actions chained together.
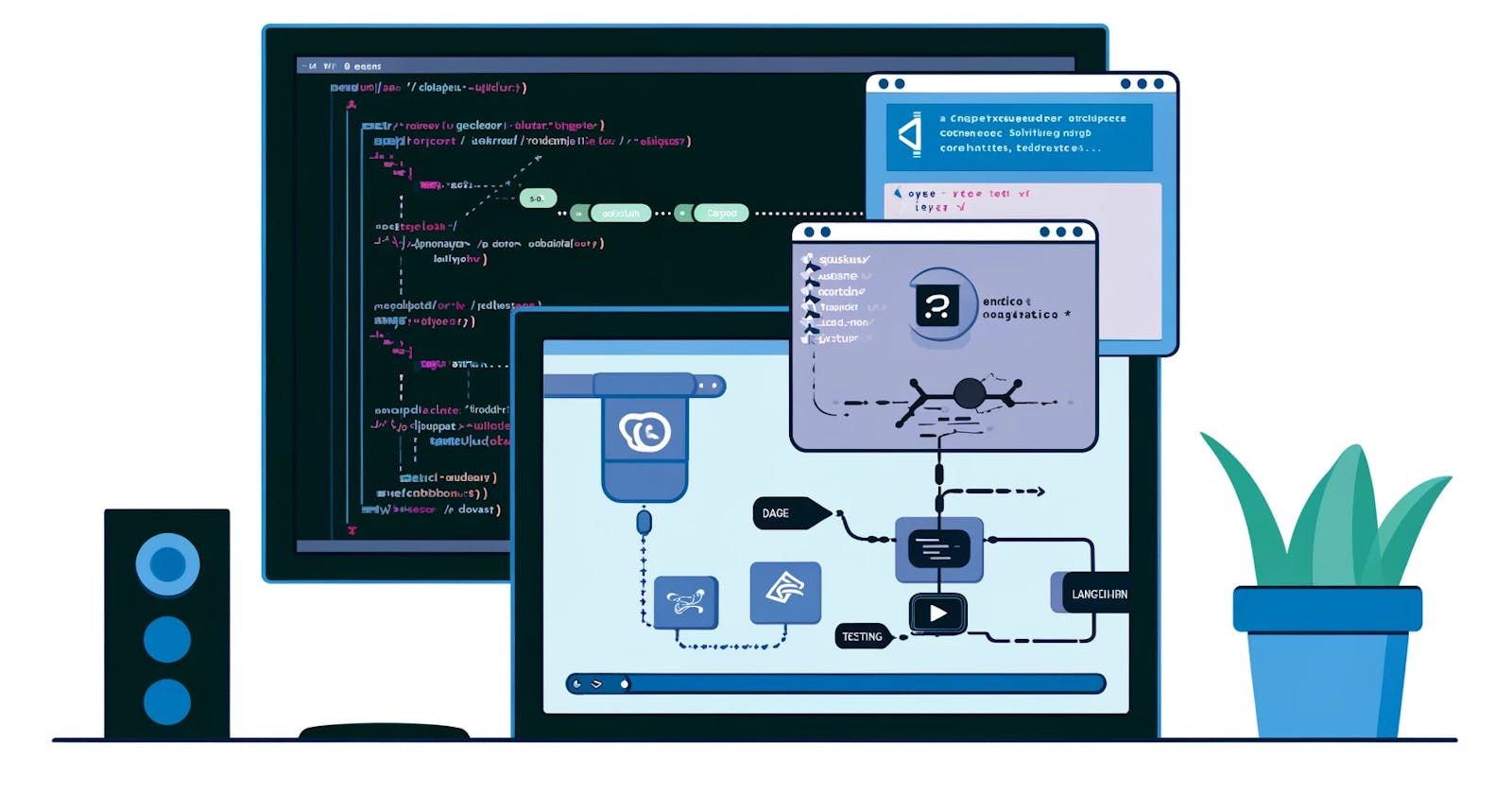
Conversational Chat to chain pipeline
Let's start off by visualizing the flow of the project

As you notice from the image, I need a way to keep track of the history of the conversation in order to use the previous responses to generate a new response. This means I need to have a chain that generates responses based on the history/context of the conversation. As a result, I leveraged the ConversationChain chain to enable interaction with the LLM Model. ConversationChain is a "versatile chain designed for managing conversations. It generates responses based on the context of the conversation."
Generate Suggestions
The first step focuses on generating suggestions of unit tests based on best practices. As described by Martin Fowler, "Unit tests have the narrowest scope of all tests in your test suite".
As best practices this translates to;
Unit tests that run quickly - "...your test suites should run fast enough that you’re not discouraged from running them frequently enough"
Use mock or fake objects to replace real implementations to isolate and focus purely on the behavior we are testing
Using readable naming conventions ensuring tests can be easily understood when a test fails
The tests must be isolated, meaning they can run in isolation
There are multiple articles detailing best practices:
https://learn.microsoft.com/en-us/dotnet/core/testing/unit-testing-best-practices
https://martinfowler.com/articles/practical-test-pyramid.html#UnitTests
Initially, I used this step to manually review and approve suggestions. I did this initially to get a better understanding of the types of suggestions I was likely to receive. Upon reaching a point where my suggestions were adequate, I lowered the temperature for more deterministic responses.
Generate code from suggestions
After suggestions are generated and improved to ensure best practices are followed, the context of the chat is used to generate code from the suggestions provided. Anecdotally, I found that AI generates better output when it is given very specific tasks. As opposed to generating unit tests out the bat, I found more accuracy generating suggestions first, ensuring the suggestions are valid and then generating code from the suggestions provided.
Include Type Annotations and correct imports for components
As a final step, I assign a different role to the model, and focus on generating type annotations and passing down the directory structure in order for the model to include the correct imports to components included in the test based on the structure of the entire project.
Write code to file
As a final step I write the tests to a specific file using shell scripts. After building and testing this module, the next step was to convert this into a Dagger module. This meant modifying certain behaviors that I could not replicate in Dagger.
Using Dagger to build a module to run my autonomous agent
There were two changes I needed to make to convert this into a Dagger module. These were; passing down the structure of the directory and exporting the output (the test file generated).
Passing down the structure of the directory
When I call my dagger module, a new session is opened with the Dagger Engine. This spins up a new container which my module will be run inside of. In my scenario, I use the withMountedDirectory command to retrieve the container along with a directory I mount. Since this directory is mounted in an isolated environment, I can run a shell script to return the structure of the src folder inside the mounted directory:
const dirStructure = await container.withExec(["tree", "/mnt/src"]).stdout()
I send this structure to the language model to give it context which it can use to correctly import components based on their relative location in the directory.
Exporting the output
I initially I assumed withMountedDirectorybind mounts the files in my host to the build in the Dagger workflow. To explain simply, bind mounting would mean that there is a link between the build and the host (so the build wouldn't necessarily contain the files contained in host, but a link), meaning if I make changes to the build this would be immediately reflected in the host file.
However, after reading through one of the GitHub Issues on the Dagger repository I learnt that withMountedDirectory is "not bind mounting the files in your machine to the build, what it does is mounting the files from your build context into your pipeline so your resulting container doesn't contain those files in the layered system." I would need to use the export function to the files from my pipeline to my host
But why....
I learnt that this is because Dagger functions "do not have access to the filesystem of the host your invoke the Dagger Functions from"
The rationale behind this is to sandbox the functions to ensure reproducibility by executing the functions in an isolated container, enabling caching the result to speed up function execution and increasing security.
Interestingly, the principles of sandboxing to provide a secure execution environment when executing code from a third party source paralleled principles I encountered compiling my module to a WebAssembly application and deploying it.
While bind mounting would be beneficial purely for my use case, upon further reading I realized that this sandboxing can avoid a scenario where I give a module (which I may not have built) access to host files without permission, increasing the risk of malicious code or security incidents being introduced to the host because of the direct link the container would have with the host.
Here's a video of me using the local versions of my dagger modules to;
Generate unit tests using AI for my SvelteKit project
Using another module I built to run my tests in a containerized environment