

Using RAG to build a chatbot to navigate the legal challenges of investing in real estate in Colombia


Background

Colombia is in the same time zone as New York, has a tropical climate and is fast becoming a strong real estate investment market for foreigners, specifically Medellin. This city has some of the highest rental yields and capitalization rates. In simple terms, you can buy residential real estate for a relatively low price in dollar terms and get good returns from rentals, specifically when you target the growing population of digital nomads and tourists from the USA.
Problem
Navigating the process of buying real estate comes with many legal challenges, especially if you are looking to invest in property abroad. While LLMs are great at solving general tasks this comes with the trade offs of domain knowledge deficiency, relying on outdated information, hallucinating responses and other general reasoning failures. To build a chatbot with the domain knowledge to more accurately answer legal issues pertaining to buying property in Colombia as a foreign national, I implemented Retrieval Augmented Generation (RAG) to provide the model with external, 'domain knowledge' to address these limitations.
After research I compiled my first set of documents to feed into the model. These documents include;
External resolutions on international exchange
Tax Statutes
Structural Tax Reform documents
Government Gazettes
Tax and Property Legislation
Implementing Retrieval Augmented Generation (RAG)
RAG combines two models; a retriever and a generator.
The Retriever Model
Not this retriever...

The retriever model identifies relevant information from the corpus of legal documents based on a query. I had to choose a database to store the corpus of data and implement a solution to efficiently search for and find relevant parts of data based on query, ensuring ease of usability of the chatbot.
Vector Indexing
To implement this task efficiently, I used vector indexes. This is a way to organize data in an array where each element can be accessed using a numerical index. Simply put, it 'is an index where the keys are vectors'.
"Vector indexes are specialized indexes designed to efficiently retrieve vectors that are closest, or the most similar, to a given vector. These indexes rely on optimized mathematical operations to efficiently identify the most similar vectors.**"**
In order to utilize vector indexing, I parsed through the url links to the legal documents I collated, extracting the text and creating vector embeddings of the text. These are numerical representations of the text where "a single mathematic vector is created against each item capturing the semantics or characteristics of each character".
But how?...
I needed to implement a pipeline that would; handle multi-lingual documentation (some of the documents are in English, others in Spanish) and convert the text into vector embeddings. This pipeline has to first standardize the text for the machine learning model that will be used to generate the vector embeddings.
Tokenization involves the task of taking a defined document and chopping it up into pieces, called tokens. In this process some certain characters like punctuations could be discarded. Each token "is an instance of a sequence of characters in some particular document that are grouped together as a useful semantic unit for processing"
Given that I am handling multi-lingual data, I opted for the BERT multilingual base model (cased). I chose BERT because it is trained to handle multilingual data.
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512)
Now that my data has been standardized I used the same model to convert the tokens to vector embeddings.
BERT (and other) models often have a large number of encoder layers/Transformer Blocks. There are twelve for the base version and 24 for the large version. Each layer passes down its output to the next layer. Language is complex, this is done in order to capture the full complexity and nuance represented by the text. Logically, this means the last layer contains the most nuanced output representing the text.
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1).squeeze().numpy()
While this creates embeddings I have to store these embeddings somewhere, after attending the MongoDB GenAI Hackaton, NYC, I learnt I could use MongoDB Atlas as a vector database and Atlas Vector Search to efficiently search my database.
But wait....
Legal documents are often verbose, as a result some of the vector embeddings were very large, exceeding the limitations for storing data in MongoDB.
If I opted to store and retrieve my embeddings using the GridFS API, this would divide the file into chunks where each chunk is a separate document. There is a tradeoff with this approach, namely; the process of splitting, tracking and then aggregating the binary data for find specific embedding could introduce additional overhead. I realized that if I segmented my embeddings and stored them in a separate document from the document containing the text, I was able to store my embeddings without hitting the 16MB threshold. I segmented the embeddings based on sections, distinguishing each section within each local document as it's own embedding, capturing distinct sections in the process. Why? because legal documents are often structured into sections representing different facets/clauses of a legislation or policies.
def update_document_embeddings():
for document in collection.find({}):
full_text = document.get("full_text", "")
if full_text:
try:
embeddings_collection.delete_many({"document_id": document["_id"]})
embeddings = generate_embeddings(full_text)
for segment_id, segment_embedding in embeddings.items():
embedding_document = {
"document_id": document["_id"],
"segment_id": segment_id,
"embedding": segment_embedding
}
embeddings_collection.insert_one(embedding_document)
except Exception as e:
print(f"Error processing document {document['_id']}: {e}")
else:
print(f"No text found for document {document['_id']}")
Retrieval
All preceding steps are pre-requisites to retrieval, you cannot retrieve what has not been stored. The purpose of my retriever is to convert whatever query I send into vector embeddings with the same model I use to create vector embeddings of the legal document. I then use Atlas Vector Search to search through the data based on the semantic meaning captured in vectors.
This step involved defining the similarity function "to use to search for top K-nearest neighbors"
After finding this data, I sort the data in terms of similarity picking the top N embeddings most relevant to my query. This is context I am using to enrich the LLM.
The Generator
I implemented a FastAPI backend, exposing an endpoint interacting with a function generating a response based on the query received and the context passed down from the retriever.
class ResponseGenerator:
def __init__(self, model="gpt-3.5-turbo"):
self.model = model
self.client = openai.OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
# async def generate(self, input_text, query):
async def generate(self, rag_context, curr_query, chat_history):
...
response = self.client.chat.completions.create(
messages=[{"role": "user", "content": prompt}],
model=self.model,
stream=True
)
try:
for chunk in response:
if chunk.choices[0].delta.content is not None:
yield f"data: {chunk.choices[0].delta.content}\n\n"
finally:
yield "event: end-of-stream\ndata: end\n\n"
Because I want to stream the response, I use the yield statement to stream text without loading everything into memory, improving the performance of my code by not waiting for the entire response to be returned from OpenAI.
Frontend
To stitch it all together, I used Sveltekit to build the frontend for the chatbot. I opted for Sveltekit primarily because this is a lightweight application. I wanted to prioritize clean code, efficiency and simplicity.
Receiving and Rendering Streamed data
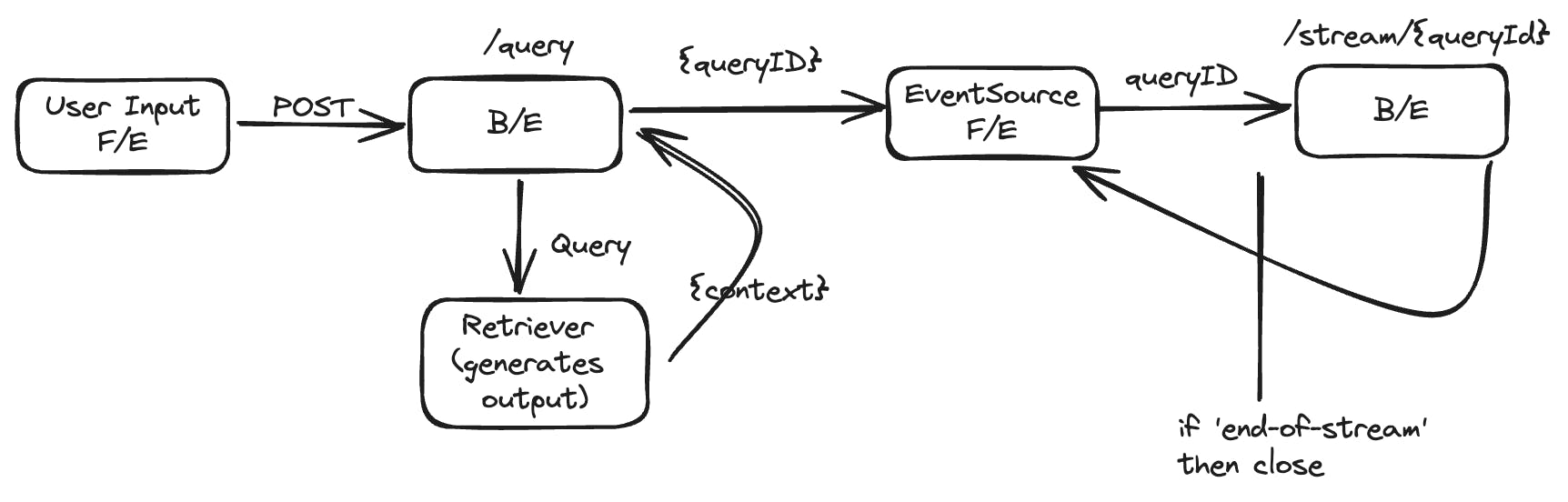
I defined a function that receives streamed data. This leveraged Server Sent Events. This opens a one-way connection, "with server-sent events, it's possible for a server to send new data to a web page at any time, by pushing messages to the web page. These incoming messages can be treated as Events + data inside the web page."
The implementation involves sending a POST request with user input from the front-end. This is received by the server. The server triggers the retriever outputting the context most related to the query. The server generates and sends back a queryId. The queryId allows the server to keep track of each unique session, ensuring the correct context is maintained when handling multiple sessions simultaneously.
An EventSource instance is opened in the frontend. This opens a persistent connection to an HTTP server, sending events. "Once the connection is opened, incoming messages from the server are delivered...in the form of events".
This connection waits to receive a message indicating that it is receiving data and a signal to close the stream.
eventSource.onmessage = function(event) {
waitingForResponse = false;
ongoingMessageContent += event.data + "\n";
messages = messages.map(msg => msg.id === activeMessageId ? {...msg, content: ongoingMessageContent} : msg);
};
eventSource.addEventListener('end-of-stream', () => {
console.log('Stream ended normally');
eventSource.close();
});
eventSource.onerror = function(error) {
if (eventSource.readyState === EventSource.CLOSED) {
console.log('EventSource closed by the server');
} else {
console.error('EventSource failed:', error);
}
eventSource.close();
};
When this function is triggered, a message is rendered.
As a next step, I intend to continue adding more relevant legal documentation to my database. Additionally, I am exploring ways to get data regarding up to date property prices to enrich the capabilities of my chatbot.
Here's a link to the deployed site:
https://propabroad.vercel.app/
Feel free to reach out to me at emmanuelsibandaus@gmail.com if you have any questions or just want to chat.